Você está desenvolvendo uma aplicação na sua estação. Cria, modifica, remove tabelas, chaves (constraints) e colunas, gera um monte de migrações (migrations) com o seu ORM favorito para manipular uma base de dados relacional e na hora do deploy o sistema quebra porque as migrações estão uma bagunça querendo remover coisas que não existem mais ou criar cosias que já existem.
Isso acontece e eu vou te mostrar aqui algumas formas de resolver.
O problema…
Na hora do desenvolvimento é normal que a gente faça muita alteração, afinal de contas, é nessa hora que podemos testar hipóteses e errar bastante, mas isso gera um certo “lixo” nas migrações que podem e vão nos dar trabalho futuramente.
Esse tipo de problema acontece normalmente com quem usa geradores de migração ou com desenvolvedores que as escrevem de forma muito simplista, assim como os geradores fazem.
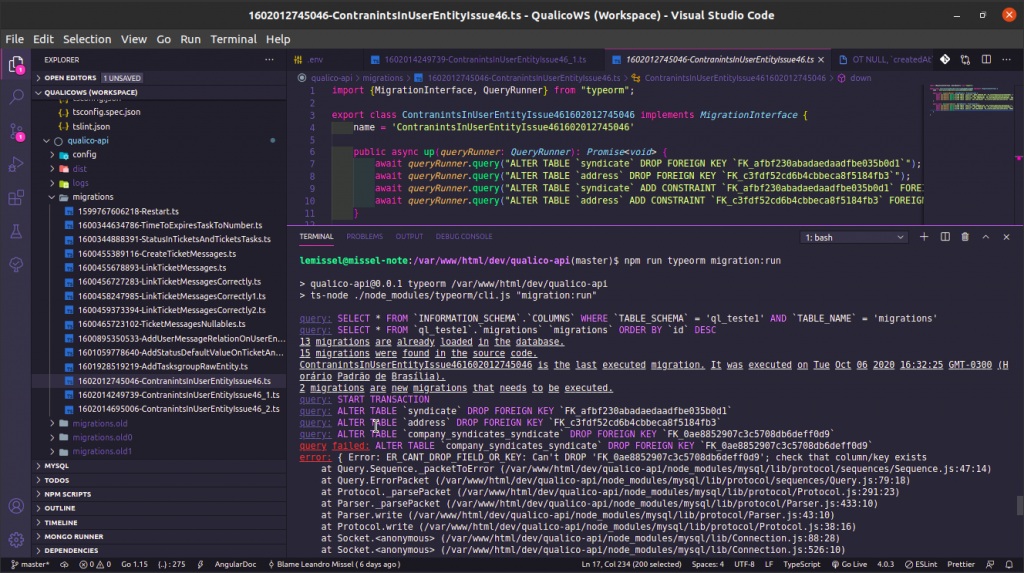
Vejamos um exemplo gerado pelo gerador de migrações do Typeorm.
import {MigrationInterface, QueryRunner} from "typeorm";
export class ModifySomething implements MigrationInterface {
name = 'ModifySomething987982495702935873450987'
public async up(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query("ALTER TABLE `syndicate` ADD CONSTRAINT `FK_sd9f8g7s8df6g89f6s87dfg` FOREIGN KEY (`addressId`) REFERENCES `address`(`id`) ON DELETE CASCADE ON UPDATE CASCADE");
await queryRunner.query("ALTER TABLE `address` ADD CONSTRAINT `FK_c76sdf8g6sdf87g6s9g67` FOREIGN KEY (`companyId`) REFERENCES `company`(`id`) ON DELETE CASCADE ON UPDATE CASCADE");
}
public async down(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query("ALTER TABLE `address` DROP FOREIGN KEY `FK_c76sdf8g6sdf87g6s9g67`");
await queryRunner.query("ALTER TABLE `syndicate` DROP FOREIGN KEY `FK_sd9f8g7s8df6g89f6s87dfg`");
}
}
Notem que ele não faz nenhuma verificação se as chaves existem ou não e em caso de uma coluna, se tem algum dado lá dentro.
Ele simplesmente sai fazendo loucamente e é isso que normalmente geram erros ao rodar as migrações. Porque o sistema tenta adicionar algo que já existe ou remover algo que não existe mais.
Forma fácil, mas…
A forma mais fácil de resolver esse tipo de problema depois que ele já aconteceu é encontrar a última migração que foi executada com sucesso, remover todas as seguintes e depois gerar uma nova migração com todas as modificações compiladas nela mesma, mas… (sempre tem um mas) se você trabalha com mais desenvolvedores, pode ser que você complique as coisas já que no commit anterior haviam as migrations com problemas e o novo tem a solução… não necessariamente vai dar problema, mas pode dar!
Faça isso por sua conta e risco, combine com o seu time e antes disso, faça backups e etc. Lembre-se que migrations servem para versionar o banco de dados e é importante manter o histórico. Depois que tudo der certo, se livre dessas tranqueiras.
Forma mais trabalhosa, mas…
A forma mais “trabalhosa” é você criar as migrações você mesmo, ou usar o código gerado pelo ORM (Typeorm nesse caso) e refatorá-lo fazendo as verificações necessárias.
Normalmente, os ORM’s oferecem funções que ajudam nesse sentido, como no caso do Typeorm que tem uma API específica para isso.
Basta você utilizar QueryRunner como injeção de dependência no seus métodos up() e down() e chamar os métodos que quiser, tais como: createTable(), createIndex(), addColumn(), createForeignKey(), getTable(), etc.
Nesse caso, o método getTable() é um método muito importante, já que ele trás as informações da tabela e com ele saberemos se a coluna a ser criada existe, se a chave estrangeira já foi criada, etc.
Então, essa é a forma mais “trabalhosa”, mas (sempre tem um mas…) a mais elegante também (você achou que vinha alguma coisa ruim aqui, certo? heheh)
Previna-se
Lembre-se que você provavelmente só está nessa situação porque não fez um bom planejamento da funcionalidade ou porque você “comitou” o código sem revisar antes e levou um monte de bugs para o seu repositório remoto.
Para prevenir isso é fácil, é só fazer as revisões, usar testes e nunca “comitar” direto na sua branch master. Caso você trabalhe sozinho (como uma “euquipe”) redobre os cuidados, pois resolver problemas de desenvolvimento é custo e você precisa de lucro, estou certo? Caso você tenha uma equipe com mais desenvolvedores, crie uma pull request e solicite as revisões de código, aos seus colegas, discuta as melhores formas de resolver o problema antes de fazer o merge para a master e evite problemas.
Não deixe seu sistema quebrar…
Quando uma migração não acontece, o seu sistema quebra e isso é ruim, certo?
Imagine você que seu sistema está funcionando “bonitamente” e na sexta-feira você tem a brilhante ideia de fazer o deploy de uma release super massinha. Está tudo indo bem, mas no último segundo para o expediente acabar a sua migração quebra e a API do seu sistema vai pro saco…
Isso aconteceu comigo e eu não quero que aconteça com você 🙂

A melhor ideia para resolver esse problema é utilizar orquestradores de containers, como o Kubernates ou Docker Swarm por exemplo.
Eles fazem um monte de coisas e uma delas é manter a API em pé e só subir a nova realease quando tudo estiver certinho.
Isso pode salvar seu final de semana e evitar muitos cabelos brancos.
Por hoje é isso aí!
Esperto muito ter ajudado.
Não esqueça de deixar um comentário bem bacana contando suas experiências e como eu posso ajudar 🙂
Grande abraço!